01
MBD-LMs
Reframes BD-LM generation as a bounded running-set of consecutive blocks, making inter-block parallelism explicit while preserving clean prefix KV semantics.
Block Diffusion Language Models (BD-LMs) make diffusion-based text generation more practical by supporting KV caching and flexible-length generation. However, native BD-LMs usually perform Single-Block Diffusion (SingleBD): each forward pass refines one noisy block conditioned on a clean cached prefix. This preserves the serving benefits of BD-LMs, but blocks are still processed sequentially.
We propose Multi-Block Diffusion Language Models (MBD-LMs), a formulation and post-training recipe for reliable Multi-Block Diffusion (MultiBD). On the model side, MBD-LMs are BD-LMs post-trained with Multi-block Teacher Forcing (MultiTF) so they can handle practical MultiBD running-set states. On the inference side, MBD-LMs decode a bounded running-set of consecutive blocks through an optimized Block Buffer runtime.
MultiTF post-training teaches the model bounded noisy block groups, heterogeneous slot-wise mask ratios, and block-causal visibility patterns.
MultiBD keeps a bounded running-set, uses Block Buffer execution, preserves prefix KV caching, commits completed blocks, and runs through Diffulex.
The training and method code lives in SJTU-DENG-Lab/mbd-lms. The executable inference runtime is Diffulex: use the Diffulex mbd-lms branch for experiment reproduction, and Diffulex main for engine development and new decoding algorithms.
Empirically, MBD-LLaDA2-Mini increases average Tokens Per Forward pass (TPF) from 3.47 to 6.19 and improves average accuracy from 79.95% to 81.03%. When combined with DMax, MBD-LLaDA2-Mini-DMax reaches an average TPF of 9.34 with only a 1.02 percentage-point average accuracy drop on math and code benchmarks.
The useful takeaway from MBD-LMs is not just "decode more blocks." The project ties together a model-side training distribution, an inference-time running-set abstraction, and a runtime path that keeps the system executable.
Reframes BD-LM generation as a bounded running-set of consecutive blocks, making inter-block parallelism explicit while preserving clean prefix KV semantics.
Constructs inference-like noisy block groups with systematic/random layouts, heterogeneous slot-wise mask ratios, and group-aware dual-stream masking.
Executes MultiBD with fixed physical block slots, dummy-slot activation, prefix-cache reuse, decode-store overlap, and CUDA Graph-friendly shapes.
Keeps method training in mbd-lms and runnable inference in Diffulex, so reproduction and new dLLM serving work have clear entry points.
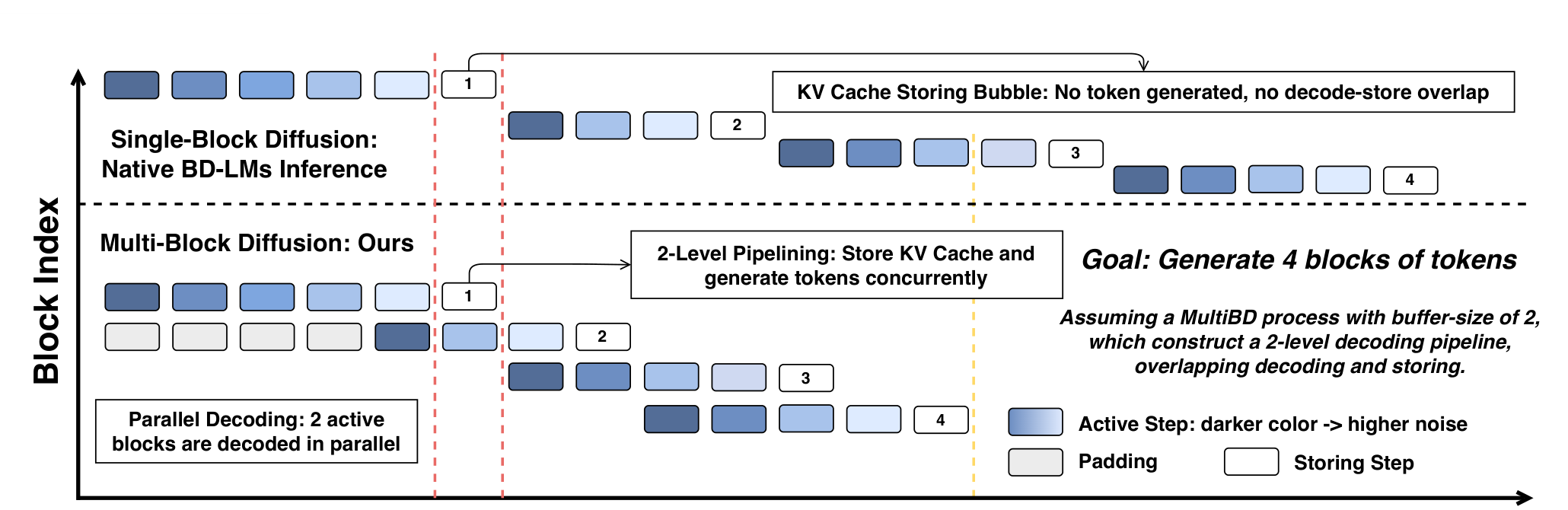
Click through the same request under SingleBD and MultiBD. SingleBD can only refine one noisy block at a time; after the block is complete, it still spends a KV-store forward pass that produces no new output. MultiBD keeps a bounded running-set, admits the next block before the front block fully leaves the buffer, and overlaps KV storing with later-block decoding.
Later blocks wait until block 1 is stored into KV.
The next block is already inside the running-set before block 1 leaves the buffer.
Diffusion Language Models (DLMs) generate text through iterative denoising and naturally support parallel token refinement. Fully bidirectional DLMs, however, are difficult to serve efficiently because they do not naturally support KV caching or dynamic-length generation. BD-LMs address this issue by generating text in block-causal form: completed blocks become a clean cached prefix, and the current block is denoised under block-causal attention.
This design gives native BD-LMs efficient intra-block parallelism, but not inter-block parallelism. In SingleBD, a later block cannot begin refinement until the current block has finished decoding and has been committed to the KV cache. The result is a storing bubble: during cache storing, no new token is generated and no decode-store overlap is exploited.
MultiBD removes this bottleneck by maintaining a small running-set of consecutive blocks. Earlier blocks in the running-set may be completed and waiting to enter the cache, while later blocks can already be active noisy blocks. This enables the model to refine future blocks while completed blocks are being committed to the KV cache.
A natural question is whether existing BD-LMs can simply run MultiBD at inference time. The paper shows that this is only partially effective. Direct MultiBD inference increases TPF, confirming that multi-block decoding relaxes the single-block bottleneck, but it can degrade accuracy because the model was not trained on practical MultiBD states.
The mismatch has two components. First, practical MultiBD does not decode an unbounded noisy suffix. It uses a bounded running-set, often with an active part around two blocks and occasional expansion to three or four active blocks. Second, active slots can have heterogeneous mask-ratio patterns: adjacent slots may differ substantially in noise level. Reliable MultiBD therefore requires training states that match both the bounded running-set structure and the slot-wise noise patterns observed during inference.
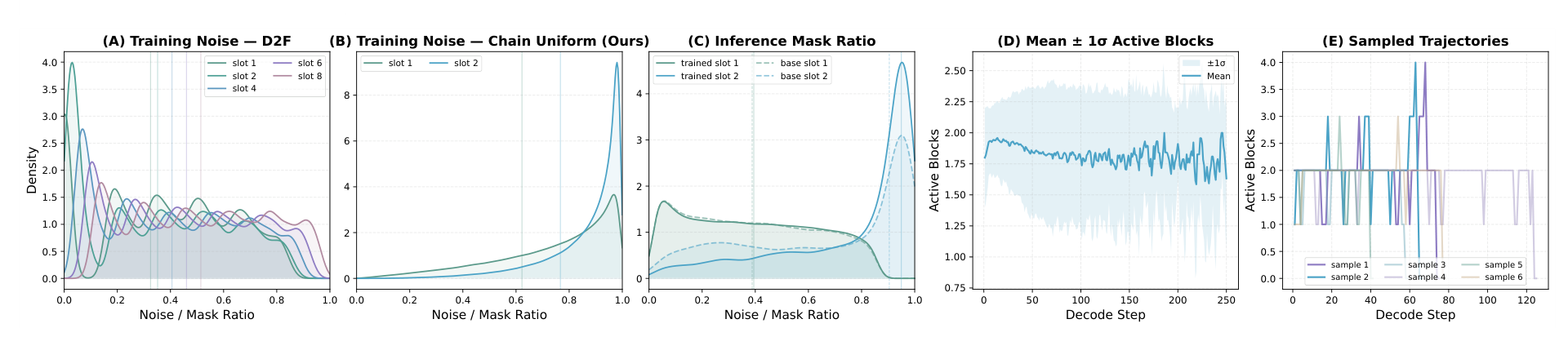
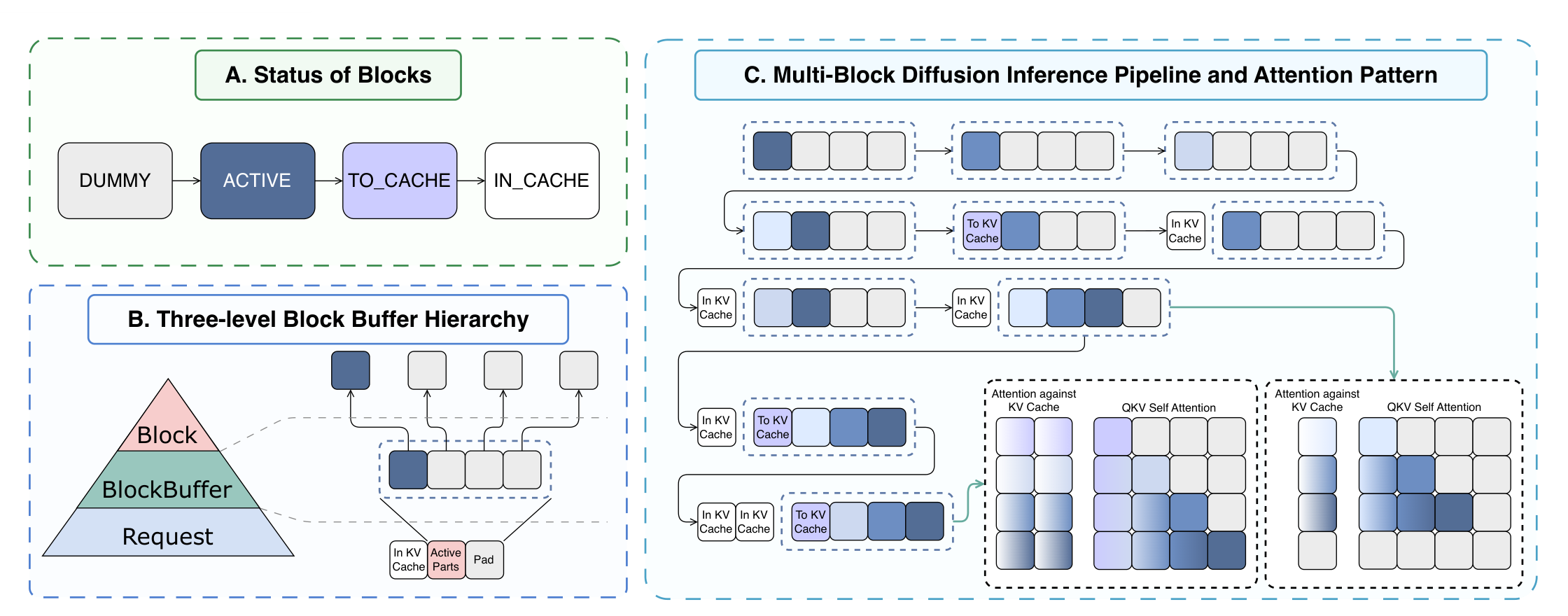
MBD-LMs formulate BD-LM generation around a running-set of consecutive blocks. At decoding step s, the running-set contains the blocks that have not yet entered the prefix KV cache. It includes active noisy blocks and completed preceding blocks waiting to be cached. Blocks before the running-set form the clean cached prefix.
This view unifies several regimes. Teacher-Forcing-trained BD-LMs correspond to the SingleBD extreme, where the model observes one noisy block conditioned on a clean cached prefix. D2F introduces visibility among multiple noisy blocks, but its training states still differ from practical MultiBD in running-set size and slot-wise noise patterns. Practical MultiBD is the bounded intermediate regime: the running-set should be larger than one to expose inter-block parallelism, but small enough to keep each forward pass efficient.
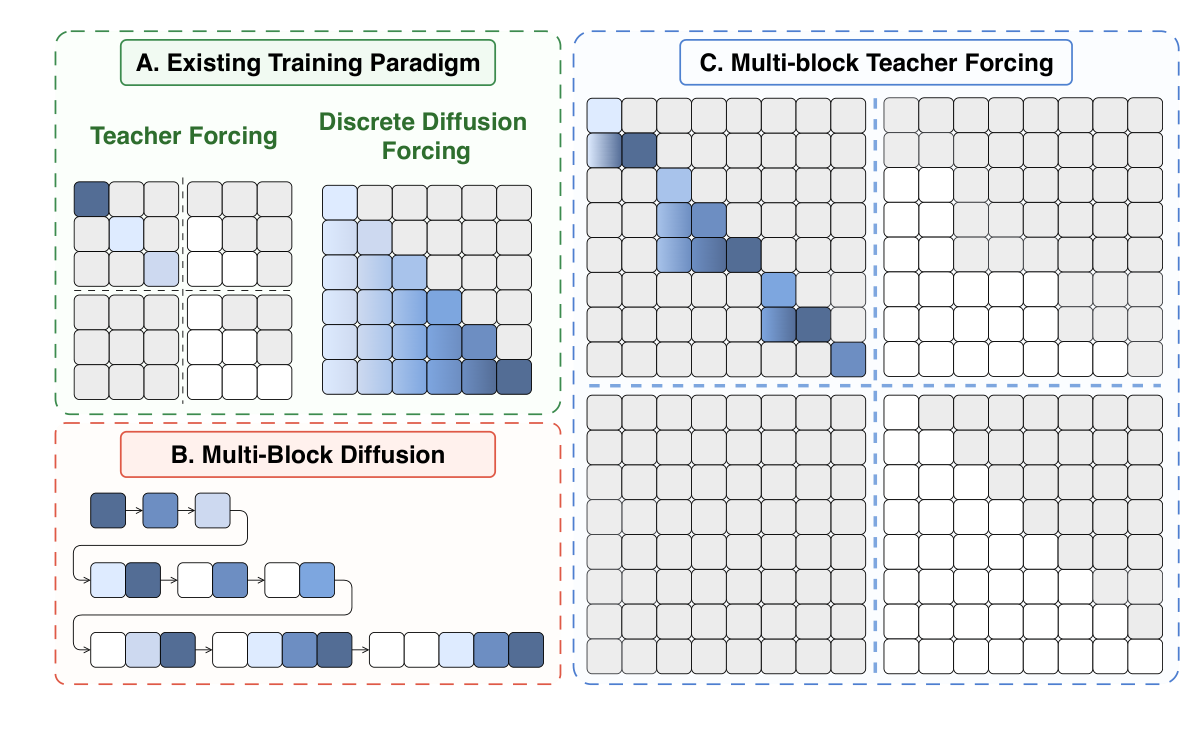
Multi-block Teacher Forcing (MultiTF) turns BD-LMs into MBD-LMs by constructing training states that resemble practical MultiBD inference. Instead of corrupting only one block as in standard teacher forcing, MultiTF corrupts a bounded group of consecutive blocks, called a noise-group, while conditioning later groups on clean earlier groups.
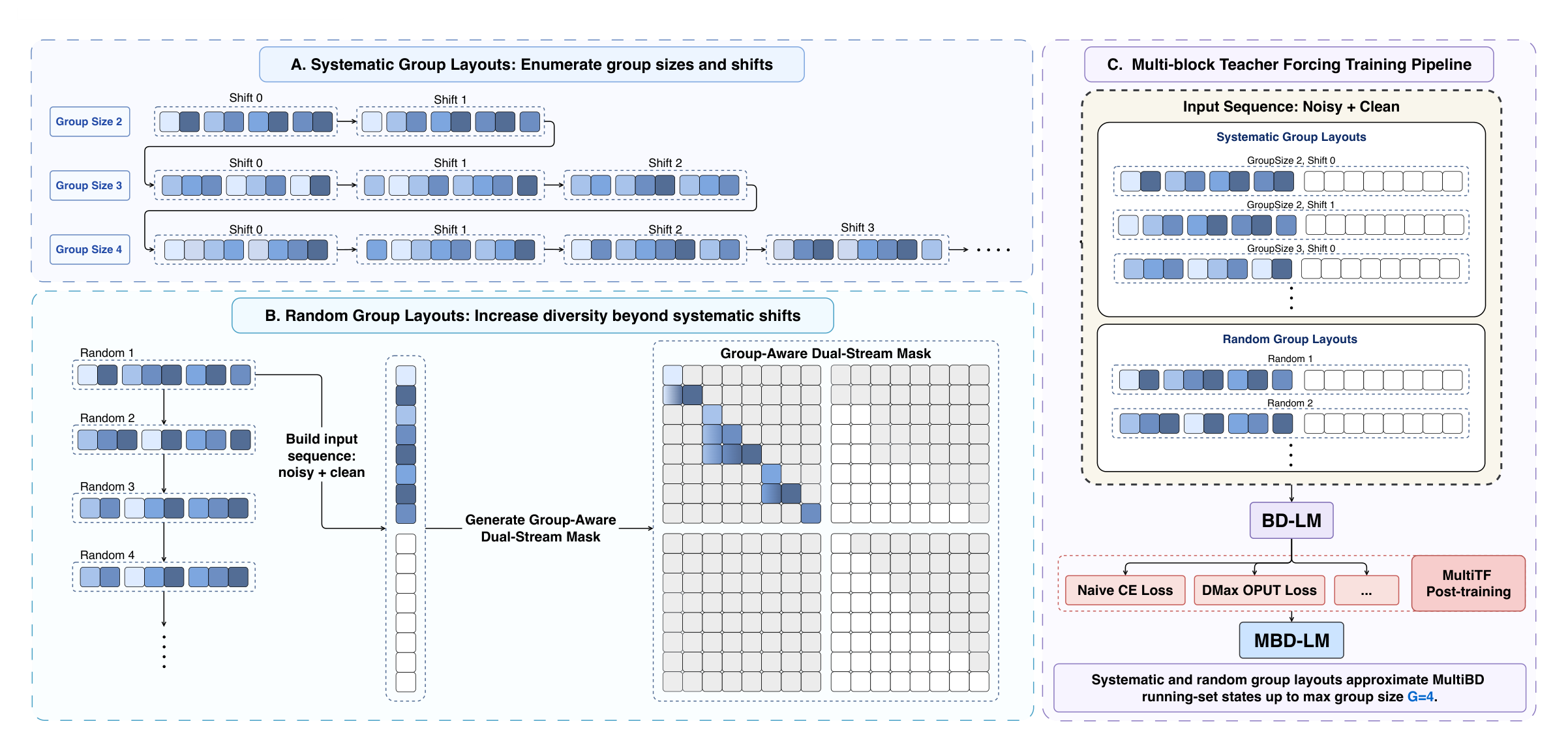
Systematic layouts enumerate group sizes and shifts so that blocks appear at different group-relative positions. Random layouts add non-regular group-size combinations and boundary patterns.
Within each noise-group, mask ratios are sampled monotonically but randomly, producing larger and more diverse slot-wise noise gaps than a fixed D2F-style monotonic schedule.
Noisy blocks inside the same noise-group can attend to each other under block-causal visibility, each noise-group can condition on its clean prefix, and clean tokens are prevented from attending to noisy tokens.
The resulting inputs are used for masked-token cross-entropy, and model-specific objectives such as DMax OPUT can be applied on top of the same MultiTF input construction.
MultiBD is useful only if the additional parallelism can be translated into wall-clock speedup. A naive implementation directly materializes the current running-set as the physical input to each forward pass. This exposes inter-block parallelism, but the number of processed tokens changes over time and across requests, making CUDA Graph capture and replay difficult.
To make MultiBD practically executable, the paper introduces the Block Buffer mechanism. A Block Buffer contains a fixed number of physical block slots. Real resident blocks inside the buffer form the logical running-set, while trailing dummy slots reserve capacity for future blocks. A future block enters decoding by activating an existing dummy slot instead of extending the physical input sequence. When the front block is completed, it is committed to the KV cache and the buffer slides forward by appending a new dummy slot at the tail.
Each slot follows the state transition dummy → active → to-cache → in-cache. This design preserves prefix-cache reuse, keeps input shapes static, overlaps decoding with KV-cache storing, and supports CUDA Graph replay.
The SJTU-DENG-Lab/mbd-lms repository is the home for the method-side work. It is where Multi-block Teacher Forcing is implemented, where training configs live, and where checkpoints are prepared before they are evaluated through the Diffulex runtime.
The repository contains the post-training path that constructs bounded noisy block groups, heterogeneous slot-wise mask ratios, and group-aware attention masks for practical MultiBD states.
Use this repo for environment setup, dataset preparation, model-specific training configs, multi-node launch scripts, and checkpoint conversion utilities.
The project page, guidelines, and figures define the SingleBD-to-MultiBD transition, MultiTF, Block Buffer inference, and the reported training/evaluation setup.
Start here when working on MBD-LM training, reproducing MultiTF data construction, or converting trained checkpoints into usable model artifacts.
Open mbd-lms Training RepoMove to Diffulex when you need benchmark execution, HTTP serving, optimized kernels, prefix caching, and system-level MultiBD runtime behavior.
Open Diffulex Reproduction BranchThe experiments evaluate mathematical reasoning on GSM8K and MATH500, and code generation on MBPP+ and HumanEval+. The paper reports Accuracy, Tokens Per Forward pass (TPF), and Accuracy Under Parallelism (AUP), where TPF measures decoding parallelism and AUP summarizes the accuracy-parallelism trade-off.
The main trend is consistent across models: MBD-LMs substantially improve TPF over native SingleBD, and MultiTF often recovers or improves the quality lost by training-free MultiBD. On LLaDA2-Mini, MultiTF raises average accuracy from 78.59% under training-free MultiBD to 81.03%, while further increasing average TPF from 4.41 to 6.19. On SDAR-8B-Chat-b32, MBD-SDAR-8B-Chat-b32 increases average TPF from 2.54 to 4.46 and improves average accuracy from 69.00% to 69.74%.
LLaDA2-Mini gains parallelism immediately, but accuracy drops before alignment training.
MBD-LLaDA2-Mini recovers quality and raises average accuracy to 81.03%.
MBD-LLaDA2-Mini-DMax reaches the highest reported average parallelism.
| Model / Setting | Avg. Accuracy | Avg. TPF | Interpretation |
|---|---|---|---|
| LLaDA2-Mini SingleBD | 79.95% | 3.47 | Native one-block baseline. |
| LLaDA2-Mini training-free MultiBD | 78.59% | 4.41 | Parallelism improves, but train-inference mismatch hurts quality. |
| MBD-LLaDA2-Mini | 81.03% | 6.19 | MultiTF aligns the model with practical MultiBD states. |
| SDAR-8B-Chat-b32 SingleBD | 69.00% | 2.54 | Second-model baseline for transfer. |
| MBD-SDAR-8B-Chat-b32 | 69.74% | 4.46 | Shows the same parallelism-quality trend beyond LLaDA2. |
| Model | GSM8K | MATH500 | MBPP+ | HumanEval+ | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | TPF | Acc | TPF | Acc | TPF | Acc | TPF | Acc | TPF | AUP | |
| LLaDA2-Mini-DMax (bufsz=2, blksz=32) | |||||||||||
| SingleBD (Native) | 91.89 | 5.70 | 76.80 | 6.13 | 72.22 | 6.14 | 77.44 | 7.44 | 79.59 | 6.35 | 459.54 |
| MultiBD (training-free) | 89.84 | 8.76 | 73.80 | 9.08 | 72.22 | 8.44 | 76.83 | 10.96 | 78.17 | 9.31 | 651.98 |
| MBD-LLaDA2-Mini-DMax | 91.74 | 8.95 | 75.00 | 9.31 | 70.11 | 8.34 | 77.44 | 10.78 | 78.57 | 9.34 | 661.28 |
| LLaDA2-Mini (bufsz=2, blksz=32) | |||||||||||
| SingleBD (Native) | 91.89 | 2.27 | 74.20 | 2.83 | 75.66 | 3.25 | 78.05 | 5.53 | 79.95 | 3.47 | 247.41 |
| MultiBD (training-free) | 92.65 | 2.76 | 73.60 | 3.53 | 72.49 | 3.97 | 75.61 | 7.37 | 78.59 | 4.41 | 301.81 |
| MBD-LLaDA2-Mini | 91.96 | 5.55 | 79.20 | 6.02 | 72.49 | 5.35 | 80.49 | 7.85 | 81.03 | 6.19 | 449.18 |
| SDAR-8B-Chat-b32 (bufsz=4, blksz=32) | |||||||||||
| SingleBD (Native) | 90.07 | 2.52 | 65.60 | 3.81 | 52.65 | 1.83 | 67.68 | 2.00 | 69.00 | 2.54 | 141.64 |
| MultiBD (training-free) | 89.01 | 2.78 | 60.60 | 5.06 | 52.12 | 1.97 | 65.85 | 2.24 | 66.89 | 3.01 | 156.35 |
| MBD-SDAR-8B-Chat-b32 | 89.16 | 3.08 | 68.00 | 5.08 | 58.99 | 4.87 | 62.80 | 4.82 | 69.74 | 4.46 | 210.42 |
| SDAR-8B-Chat-b4 (bufsz=4, blksz=4) | |||||||||||
| SingleBD (Native) | 91.05 | 1.33 | 72.80 | 1.46 | 64.80 | 1.13 | 73.70 | 1.07 | 75.59 | 1.25 | 85.46 |
| MultiBD (training-free) | 90.45 | 2.39 | 70.60 | 2.68 | 65.80 | 1.55 | 74.39 | 1.47 | 75.31 | 2.00 | 129.59 |
| MBD-SDAR-8B-Chat-b4 | 91.81 | 2.28 | 72.40 | 2.52 | 64.29 | 2.62 | 72.56 | 2.24 | 75.27 | 2.42 | 148.65 |
Ablations further support the training-state alignment story. Combining systematic and random layouts gives the best AUP among the layout variants. Replacing the chain-uniform scheduler with other schedulers reduces the accuracy-parallelism trade-off; in particular, the D2F-style monotonic scheduler causes a large accuracy drop in the reported ablation, indicating that noisy-block visibility alone is not sufficient when slot-wise noise patterns are mismatched.
| Model | GSM8K | MATH500 | Average | ||||
|---|---|---|---|---|---|---|---|
| Acc | TPF | Acc | TPF | Acc | TPF | AUP | |
| LLaDA2-Mini-CAP (bufsz=2, blksz=32) | |||||||
| SingleBD (Native) | 91.74 | 3.08 | 77.80 | 3.71 | 84.77 | 3.40 | 247.30 |
| MultiBD (training-free) | 91.21 | 4.00 | 77.20 | 4.94 | 84.21 | 4.47 | 319.17 |
| LLaDA2.1-Mini (bufsz=2, blksz=32) | |||||||
| SingleBD (Native) | 93.03 | 4.12 | 81.40 | 4.87 | 87.22 | 4.50 | 390.64 |
| MultiBD (training-free) | 92.27 | 5.80 | 81.00 | 7.20 | 86.63 | 6.50 | 558.52 |
| Configuration | Acc | TPF | AUP |
|---|---|---|---|
| SingleBD (Native) | 84.67 | 6.57 | 536.89 |
| + systematic layouts | 83.22 | 9.71 | 774.03 |
| + random layouts | 82.72 | 9.42 | 747.46 |
| systematic + random layouts (ours) | 84.59 | 9.87 | 805.34 |
| Configuration | Acc | TPF | AUP |
|---|---|---|---|
| SingleBD (Native) | 84.67 | 6.57 | 536.89 |
| D2F-style monotonic scheduler | — | — | — |
| random scheduler | 83.14 | 9.70 | 771.74 |
| sorted-uniform scheduler | 81.28 | 9.73 | 748.73 |
| chain-uniform scheduler (ours) | 84.59 | 9.87 | 805.34 |
Higher TPF does not automatically imply proportional wall-clock speedup because MultiBD processes a larger static Block Buffer at each forward pass. The paper therefore separates useful committed tokens from the per-step computational workload. Increasing the buffer size can improve throughput when the useful-token gain outweighs the extra per-step cost introduced by resident blocks and dummy slots.
Engine version note. Table 3 was measured with the older Diffulex release used by the public mbd-lms reproduction branch. Current Diffulex is faster, but we have not refreshed this exact H100 TP=2 result because we do not currently have access to an H100 machine with CUDA 13 under the original setting.
On the legacy H100 TP=2 setup reported in Table 3, MBD-LLaDA2-Mini increases average TPF from 3.47 to 6.19 while step latency rises from 7.07 ms to 8.78 ms. The measured average TPS increases from 517.16 to 745.92. With DMax, MBD-LLaDA2-Mini-DMax increases average TPF from 6.35 to 9.34, and average TPS rises from 779.49 to 926.67 in the same table.
| Model | Forward-step statistics | Realized throughput | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Avg. TPF | TPF Gain | Step Lat. (ms) | Lat. Cost | GSM8K TPS | MATH500 TPS | MBPP+ TPS | HumanEval+ TPS | Avg. TPS | TPS Gain | |
| LLaDA2-Mini | 3.47 | — | 7.07 | 1.00x | 344.05 | 403.45 | 496.19 | 824.94 | 517.16 | — |
| MBD-LLaDA2-Mini | 6.19 | +78.39% | 8.78 | 1.24x | 687.87 | 707.89 | 646.73 | 941.18 | 745.92 | +44.24% |
| LLaDA2-Mini-DMax | 6.35 | +83.00% | 9.02 | 1.28x | 700.82 | 730.60 | 754.97 | 931.55 | 779.49 | +50.73% |
| MBD-LLaDA2-Mini-DMax | 9.34 | +169.16% | 11.20 | 1.58x | 834.52 | 851.07 | 896.65 | 1124.43 | 926.67 | +79.19% |
A formal arXiv record is on the way. Until then, please cite MBD-LMs with the temporary BibTeX entry below.
@misc{jin2026mbdlms,
title = {Multi-Block Diffusion Language Models},
author = {Yijie Jin and Jiajun Xu and Yuxuan Liu and Chenkai Xu and Yi Tu and Jiajun Li and Dandan Tu and Xiaohui Ye and Kai Yu and Pengfei Liu and Zhijie Deng},
year = {2026},
note = {arXiv on the way}
}