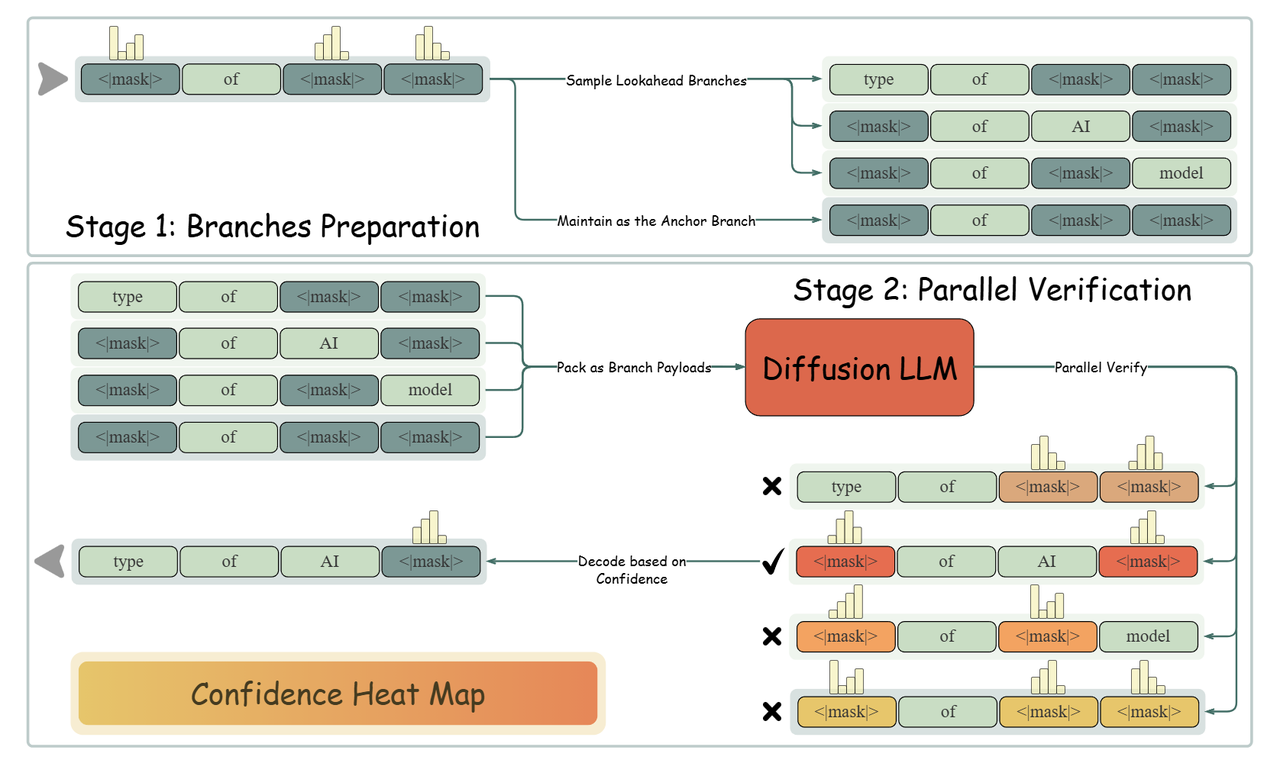
LoPA: Scaling dLLM Inference via Lookahead Parallel DecodingDecember 18, 2025Chenkai Xu*, Yijie Jin*, Jiajun Li, Yi Tu, Guoping Long, Dandan Tu, Mingcong Song, Hongjie Si, Tianqi Hou, Junchi Yan, Zhijie Deng †
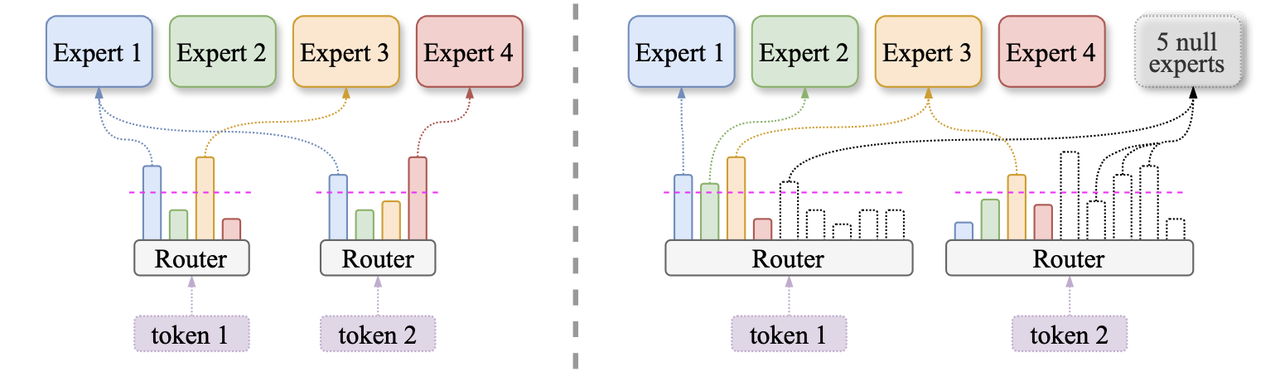
AdaMoE: Token-Adaptive Routing with Null Experts for MoESeptember 8, 2025Zihao Zeng*, Yibo Miao*, Hongcheng Gao, Hao Zhang, Zhijie Deng†
AdaMoE: 借助“空专家”实现Token级别的动态路由选择September 8, 2025Zihao Zeng*, Yibo Miao*, Hongcheng Gao, Hao Zhang, Zhijie Deng†
SIFT: Grounding LLM Reasoning in Contexts via StickersFebruary 21, 2025Zihao Zeng, Xuyao Huang*, Boxiu Li*, Zhijie Deng†
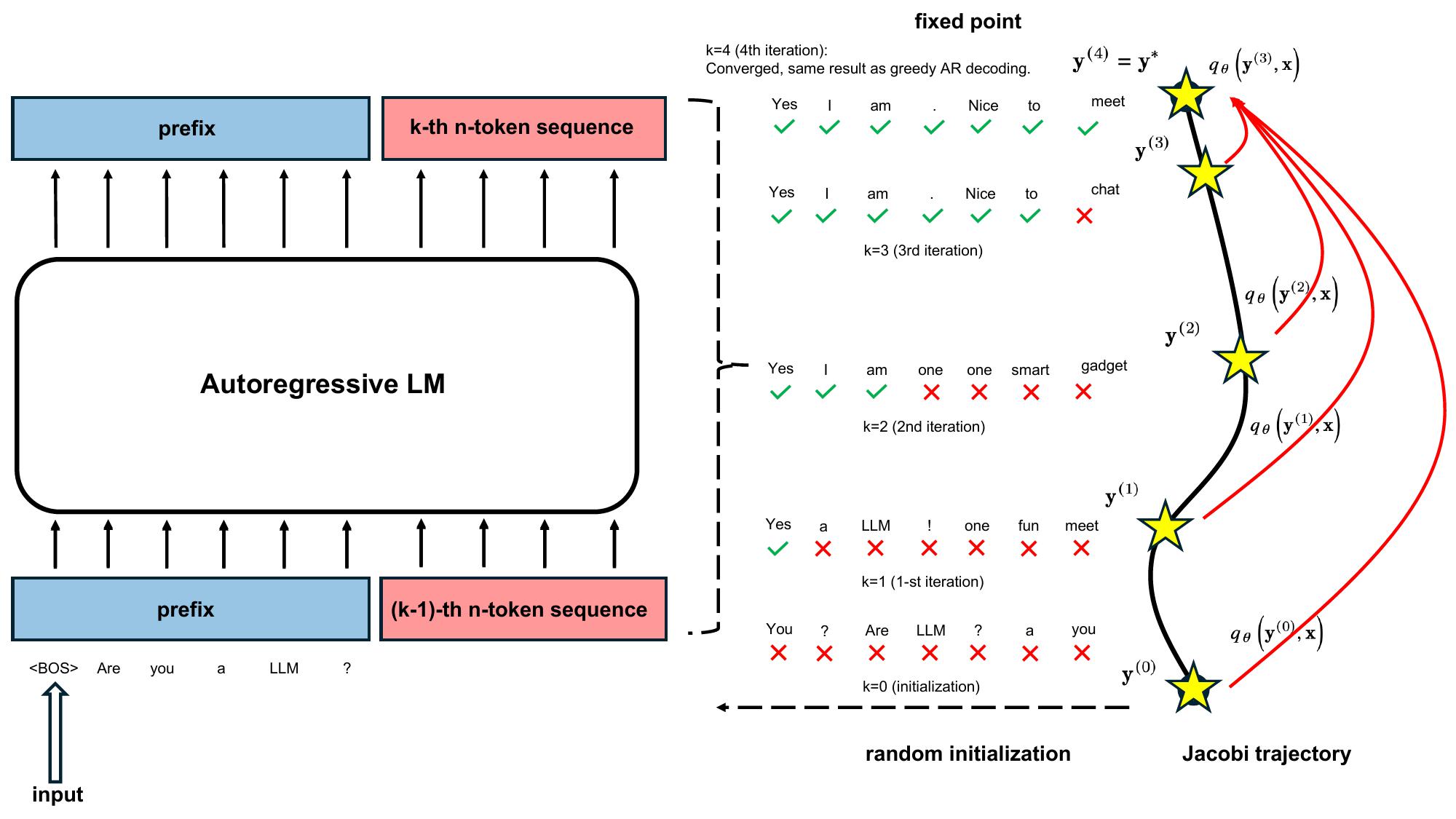
Consistency Large Language Models: A Family of Efficient Parallel DecodersMay 6, 2024Siqi Kou*, Lanxiang Hu*, Zhezhi He, Zhijie Deng†, Hao Zhang